A Primer on Git Internals
Why in the world would you ever need to understand Git Internals?
Because
-
the git commands which you probably memorized, would make a lot more sense.
-
the official docs contain a lot of terminologies which you would be unfamiliar with, if you donot know the internals.
-
its fun learning about how things work.
Lets cover some pre-requisites before getting into the main topic.
- Hashing: Its a "one-way" conversion of data of any length into a fixed size bunch of characters(called hash). One key feature of hashing is that, no two different data can produce the same hash. Even data that differ by just one character will produce very different hashes. Here is a comparision of hashing two words(using SHA1 hashing algorithm) that differ by just a single letter:
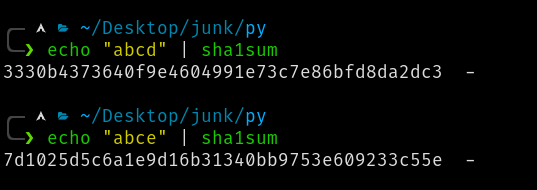
Why did we learn about something completely unrelated to git? Because hashing is used extensively in git to give unique id to every file irrespective of how minor the changes are. Git uses SHA1 hashing algorithm for hashing objects.
Git Objects
Git objects are the basic fundamenal blocks of a repository. There are 3 types of Git objects:
- Blob
- Tree
- Commit
Blobs
Binary Large OBject(or simply, blob) is a type of file which stores only data. Typically, when you create file in your computer, it has 2 things: data and metadata. The contents of the file is called the "data" of the file. Things like filename, time of creation, created by, etc are called the "metadata" of the file.
Whenever you add a file (git-add) into the git repository, git first creates a blob from that file(this blob is just the contents of the file) and then generates an unique id of that blob using SHA1 hash. This id will be used to reference this blob in the entire repository. More specifically, this id will be used in git-trees to reference the blob.
Trees
A tree is a data structure of connected nodes. Each node can have multiple children but must have only one parent.
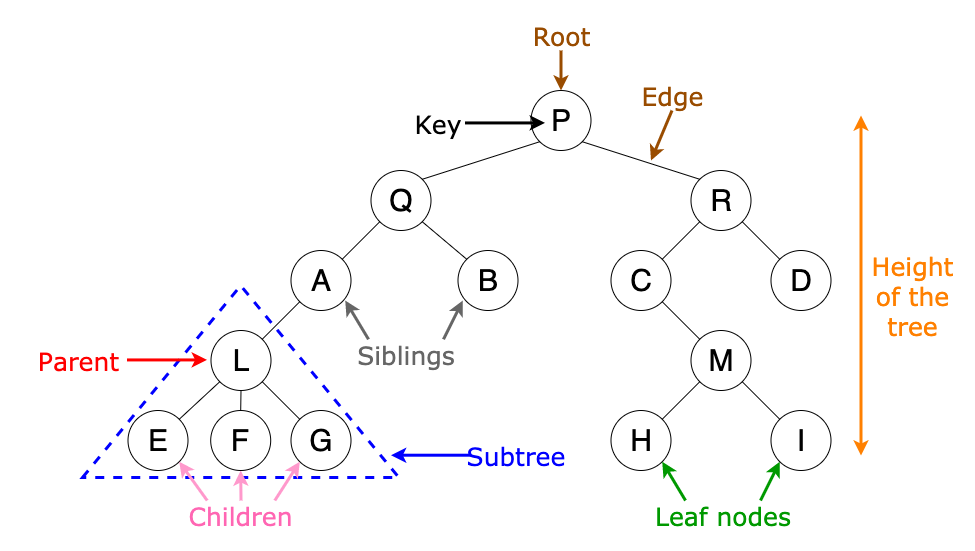 Git uses trees to keep track of blobs and sub folders inside a repository.
Git uses trees to keep track of blobs and sub folders inside a repository.
A git tree is a list of all the blobs/folders(sub trees). The root directory(/) of a project is the root tree of the repository. Like blobs, every tree has a unique id generated by the SHA1 hash of the contents of the tree. This id will be used by its parent tree to reference it. The id of the root tree will be used by a git-commit object to reference it.
This is how a git-tree looks like:

This is root tree of the repository. Its just a list of entries(its children).
The blob of 1.c has only the contents of the file 1.c. This blob is identified by its SHA1 hash (b28b04...). The first entry says:
The object identified by b28b04... is a blob having filename 1.c and permissions 100644.
Commits
A git commit is a just a pointer which points to two things : The previous commit(if exists) and the root tree of the project. Apart from that, it also contains data like commit author, commit date, commit message etc. Every commit also has unique id generated using SHA1 hash of its contents. This commit hash is the one generally exposed to the developer. You can move between commits using their commit hash.
To recap, this is how a repository will look internally:
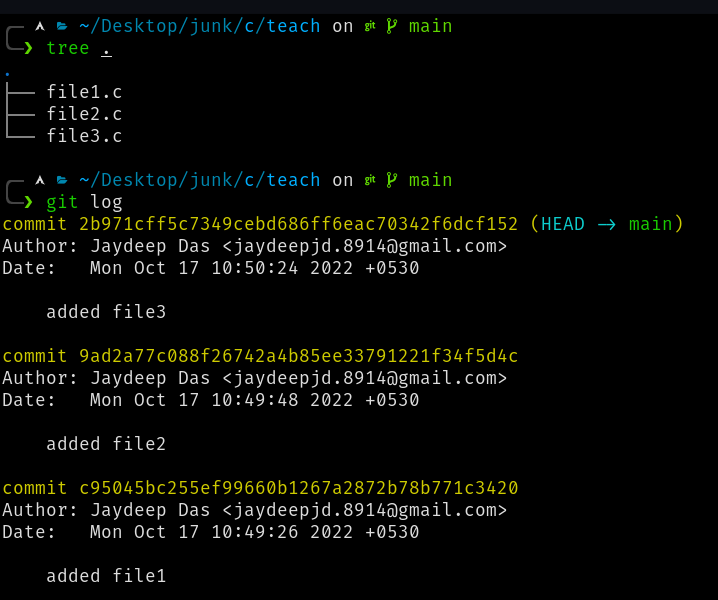
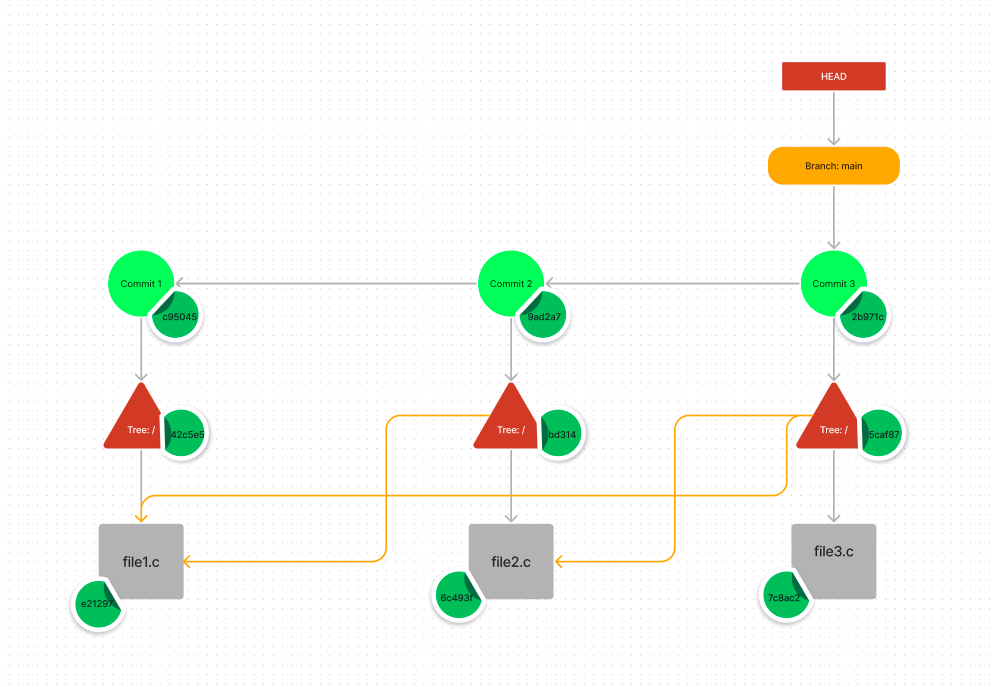
Every time you commit, Git takes the snapshot of the entire repository. This might mislead someone to believe that the same files are copied again and again in every commit. However this is not true.
Notice how git is not "resaving" unchanged files to the repository. In tree 5caf87, only file3.c is newly introduced. file2.c and file1.c
which were introduced in previous trees, are just pointed by 5caf87.
There are still a lot of things that I want to share in this blog but unfortunately, it would be too long and will not retain reader's attention. So, I will cut this blog short and be posting the latter parts in my blogpost.